|
|
|
 |
|
The Havasu Data Integration System
- A data integration system provides an automated method for querying
across multiple heterogeneous databases in a uniform manner.
Essentially a query on the mediated schema is routed to
mutiple data sources that cumulatively project the schema. The mediated
schema can be provided as a view on the sources in the system or it can
represent a particular application scenario and the data sources can be
seen as views on this mediated schema. Till date all data integration
systems give guarantees about cost of answering a user query. Havasu on
the other hand tries to provide a guarantee on both the cost of
answering a query and the number of answers to the query i.e. we
jointly optimize both the cost and coverage of the plans. Since we want
to give the best guarantees for coverage, we will end up calling all
the sources known to the mediator. To be cost effective we then look at
parallel plans to answer the queries. Source statistics needed to optimize the query plans are not easily available since sources are
independent and hence StatMiner (Statistics Mining module) approximates the statistics like coverage and overlap of sources by
using mining algorithms. The execution engine of Havasu will show adaptiveness in terms of
data source sizes, network conditions,
and other factors.
Havasu Architecture
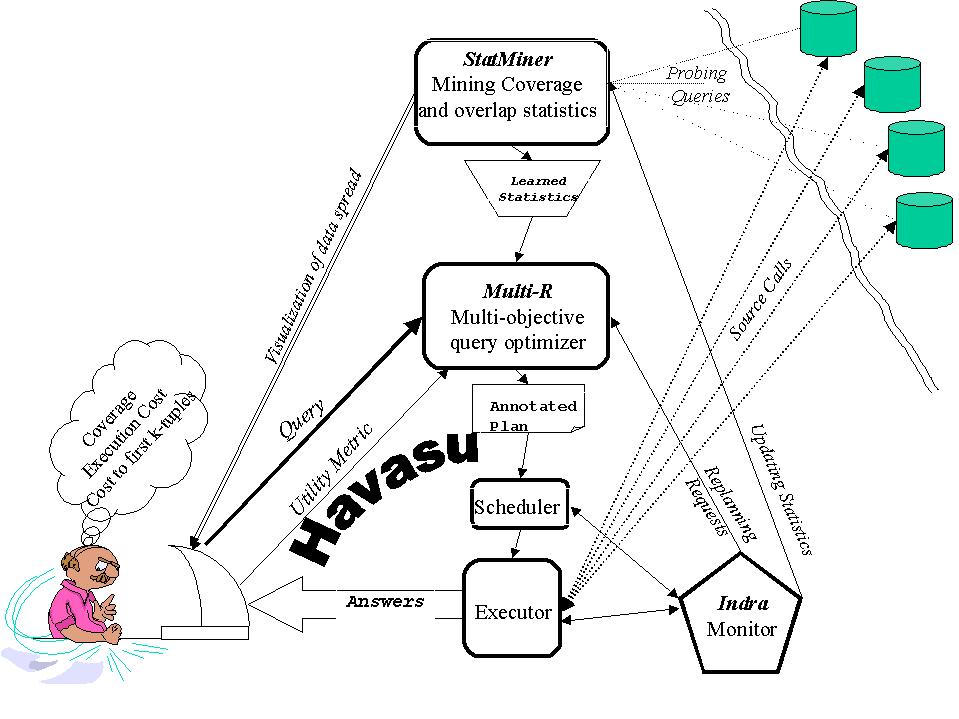
- Joint Optimization of Cost & Coverage
Existing approaches for optimizing queries in information
integration use decoupled strategies, attempting to optimize coverage
and cost in two separate phases. Since sources tend to have a variety
of access limitations, this type of phased optimization of cost and coverage
can unfortunately lead to expensive planning as well as highly
inefficient plans. We present techniques for joint
optimization of cost and coverage of the query plans. Our algorithms
search in the space of parallel query plans that support multiple
sources for each subgoal conjunct. The refinement of the partial plans
takes into account the potential parallelism between source calls, and
the binding compatibilities between the sources included in the plan.
We introduce a new query plan representation and show that our way of
searching in the space of parallel plans can improve both the plan generation
and plan execution costs compared to existing approaches.
We provide both a System-R style query optimization algorithm as
well
as a greedy local earch algorithm for searching in the space of such query plans.
- Mining Source Coverage Statistics
Recent work in data integration has shown the importance of
statistical information about the coverage and overlap of sources for
efficient query processing. Despite this recognition there are no effective
approaches for learning the needed statistics. The key challenge in learning
such statistics is keeping the number of needed statistics low enough to have
the storage and learning costs manageable. Navie approaches can become
infeasible very quickly. We present a set of connected techniques that
estimate the coverage and overlap statistics while keeping the needed
statistics tightly under control. We use a hierarchical classification
of the queries, and threshold based variants of familiar data mining
techniques to dynamically decide the level of resolution at which to
learn the statitics.
Project Members
- Professor Subbarao
Kambhampati.
- Zaiqing Nie is
working on the Havasu Parplan Optimizer. He is also involved in learning
statistics for the sources taking part in the Havasu Integration system.
- Ullas Nambiar is
developing the StatMiner for Havasu. He is also working on developing the
adaptive execution engine for Havasu.
- Sreelakshmi Vaddi is
working on developing the adaptive execution engine for Havasu with a focus
on ranked query results.
Publications
-
A frequency-based approach for mining coverage statistics in Data
Integration.
Zaiqing Nie and Subbarao Kambhampati. ICDE 2004 (To appear).
-
Bibfinder/Statminer: Effectively mining and using Coverage and Overlap
Statistics in Data Integration
Zaiqing Nie, Subbarao Kambhampati and Thomas Hernandez.
Proc. VLDB 2003. Here is the
poster
-
Frequency-based Coverage Statistics Mining for Data Integration.
Zaiqing Nie, Subbarao Kambhampati.
IJCAI Workshop on Information Integration on the Web. 2003.
-
Answering Imprecise Database Queries
Ullas Nambiar and Subbarao Kambhampati. ACM WIDM 2003 (Workshop on Web
Information and Data Management).
- S. Kambhampati, U. Nambiar, Z. Nie and S. Vaddi Havasu: A Multi-Objective, Adaptive Query Processing Framework for Web Data Integration ASU CSE TR-02-005.
-
Z.Nie, U. Nambiar, S. Lakshmi and S. Kambhampati. ASU CSE TR
02-009.
Mining
Coverage Statistics for Websource
Selection in a Mediator
(A short version of this
paper appears in Proceedings of CIKM
2002).
- Z. Nie,S. Kambhampati,U. Nambiar and S. Vaddi
Mining Source Coverage Statistics for Data Integration. in Proceedings of the 3rd Intl. Workshop
on Web Information and Data Management (WIDM'01), Atlanta, Georgia, November 9, 2001.
- Z. Nie and S. Kambhampati Joint Optimization of Cost and Coverage of Information Gathering Plans. In Proceedings of the 10th ACM International Conference on Information and Knowledge Management (CIKM), Atlanta, Georgia, November 2001.
- Z. Nie and S. Kambhampati Joint Optimization of Cost and
Coverage of Information Gathering Plans..
ASU CSE TR 01-002.
|
