CSE 471/598 Intro to AI (Kambhampati)
Homework 5 Solutions
Question IV [Short answer questions:
ProblemVI. [30pt] George Costanza wants to throw
a party and he wants it to be a success. Over the years he has thrown a fair
number of parties, and some have been successful and some have been
unsuccessful. He typically calls some subset of Seinfeld, Newman and Kramer.
Here is the data about the past parties--described in terms of who turned up at
the party and whether the party was a success.



|
|
Seinfeld invited |
Newman invited |
Kramer invited |
Good Party |
|
Party1 |
N |
N |
N |
N |
|
Party2 |
N |
N |
Y |
N |
|
Party3 |
N |
Y |
N |
Y |
|
Party4 |
N |
Y |
Y |
Y |
|
Party5 |
Y |
N |
N |
Y |
|
Party6 |
Y |
N |
Y |
Y |
|
Party7 |
Y |
Y |
N |
N |
|
Party8 |
Y |
Y |
Y |
N |
Part A.[3pt] We want to help George out by using
decision trees to learn the pattern behind successful parties, so that George
can then use the learned decision tree to predict whether or not a new party he
is trying to throw will be a success. Since this is a small-enough example, YOU
should be able to see the pattern in the data. Can you express the pattern in
terms of a compact decision tree (If you are completely lost on this part,
you can ask me for a hint at the expense of some points; so you can continue
with the rest of the sub-parts)
Clearly, as any
true-blue seinfeld aficianado will have no trouble recognizing, the party will
be bad if both seinfeld and Newman are invited (they are sworn enemies,
afterall), and will be good otherwise.
So, the concept is
~(Seinfeld .xor. Newman)
Part B.[6pt] Suppose you want to go with the
automated decision-tree construction algorithm (which uses the information
value of splitting on each attribute). Show the information values of splitting
on each attribute, and show which attribute will be selected at the first
level. Assume that if two attributes have the same information value, you will
split the tie using the alphabetical ordering (this should be a reasonable
assumption since decision trees don't care how you choose among equally valued
attributes).
There are 4 parties with Seinfeld yes and 4
with seinfeld no.
In each set, 2 are good parties and 2 are
bad
So, I(seinfeld) = 4/8 I(2/4,2/4) + 4/8 I(2/4,2/4)
= .5 * 1 + .5 * 1 ( as
I(1/2,1/2) is 1)
= 1
Similar reasoning lets
us realize that I(Kramer) = I(Newman) = 1
Since original set has
4 good and 4 bad parties, the information in the initial set is 1 too.
So, information gain
associated with each of the attributes is 0.
Since all have same
information gain, we break tie in alphabetical order, picking Kramer first
Part C.[3] Do you think the tree that you will
ultimately get by continuing to refine the partial tree in Part B will be
better or worse than the tree that you wrote in Part A If it is worse, is it
theoretically consistent that you could do better than the automated
information-theoretic method for constructing decision trees (You don't need
to show any explicit information value calculations here).
Since we picked cramer first, we will wind up
making a tree which will refer to all attributes (since we know that the good
or bad party depends on seinfeld and newman and that cramer is a basically
irrelevant question).
Clearly, the resulting tree is worse than the
smallest tree we can get by just realizing that it is an XOR concept on
Seinfeld and Newman.
Since we are using a greedy approach we are not
guaranteed to get smallest tree.
Part D.[4] Consider the super-attribute
"Seinfeld-Newman", which in essence is the result of merging the
seinfeld and newman attributes. This super attribute takes four values: YY, YN,
NY, NN. Compute the information value of this super-attribute, and compare it
to the attribute information values in Part B. If you had a chance of
considering this super attribute along with the other attributes, which would
you have chosen to split on at the first level
For this case, the
super attribute splits the examples as follows
YY 0+ 2-
YN 2+ 0-
NY 2+ 0-
NN 0+ 2-
2/8 I(0,1) + 2/8
I(1,0) + 2/8 I(1,0) + 2/8 I(0,1)
= 0
So the information
gain is 1-0=1
Thus if you have this
super attribute, clearly it has the best gain—compared to others which are all
0.
If we choose that
super attribute, then we will get a single layer tree in terms of that
attribute, which can be translated into a two layer tree interms of the single
attributes.
Part E.[4] Does the answer to Part D suggest you
a way of always getting optimal decision trees If so, what is the
computational cost of this method relative to the standard method (that you
used in Part B)
Yes, the idea is to
consider not just single attributes but also super attributes corresponding to
subsets of all attributes. Unfortunately however, there are 2N super
attributes and single attributes, given the N single attributes. This will make the node ordering an
exponential cost operation!
Part F.[4] Now, George is gettin' upset at all
this dilly-dallying with the decision trees, and would like to switch over to neural
networks for finding pattern in his successful parties. What is the minimum
number of layers of threshold units that he would need in his neural network so
he can converge and learn the pattern behind his successful parties Explain
how you reached your answer.
Since we know that the
underlying concept is an XOR on two of the three attributes, we know that we
cannot get by with a single layer
perceptron. We need at least 2 layers. (Since XOR is not linearly separable).
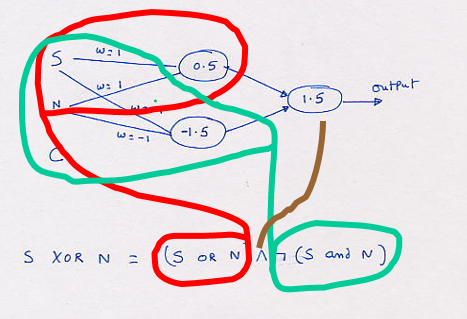
Part G.[6] Show an actual neural network (with
weights and thresholds) that represents the concept. Assume that the inputs are
going to be 1 (for Y) and 0 (for N). We want the output to be 1 (for successful
party) and 0 (for unsuccessful party). I am not asking you to learn a network using
the gradient descent method. I am asking you to show one directly. (hint 1: Use
your answer to part A). (Hint 2: You might want to consult figure 19.6 in
page 570 of the textbook in doing this problem.)